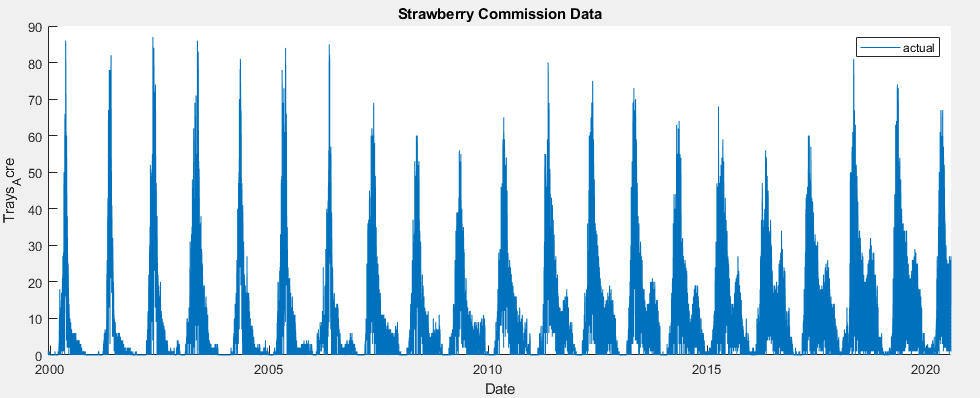
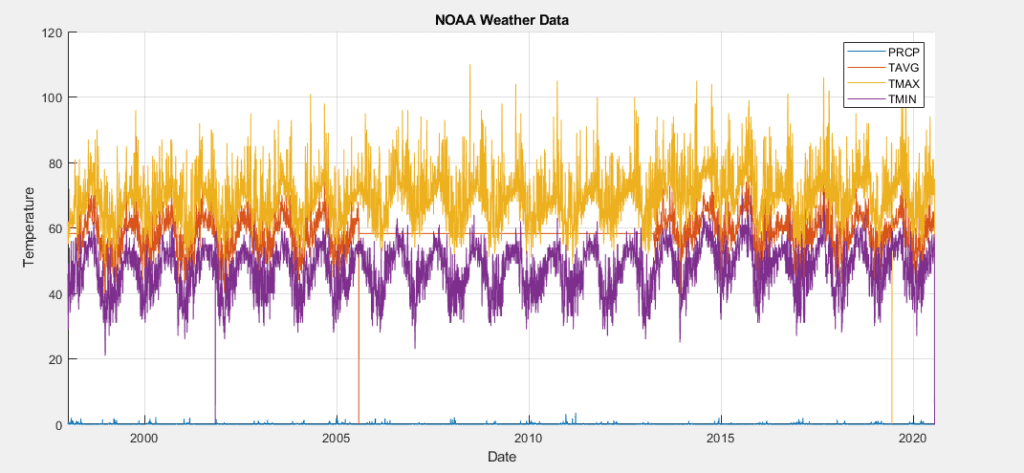
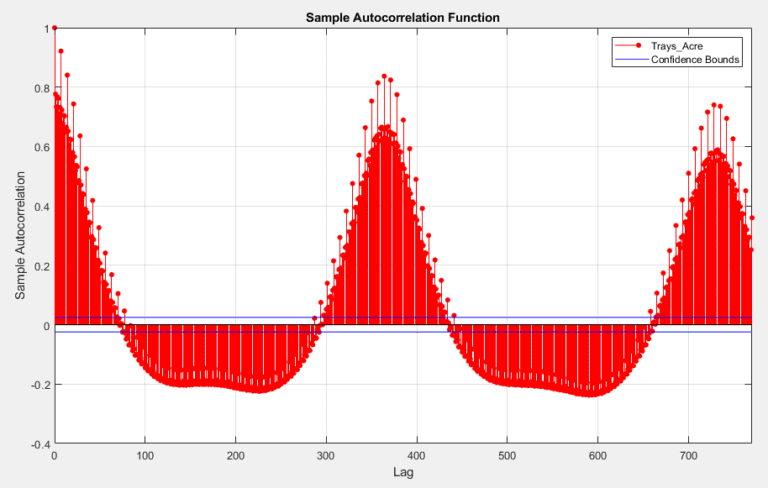
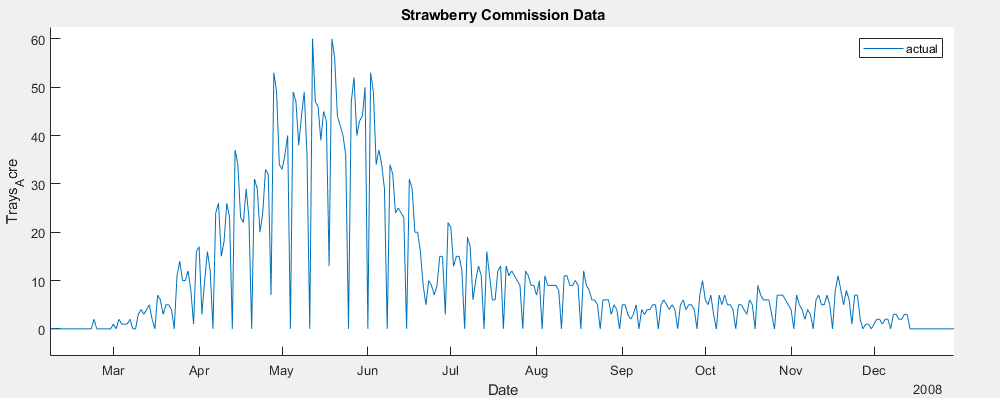
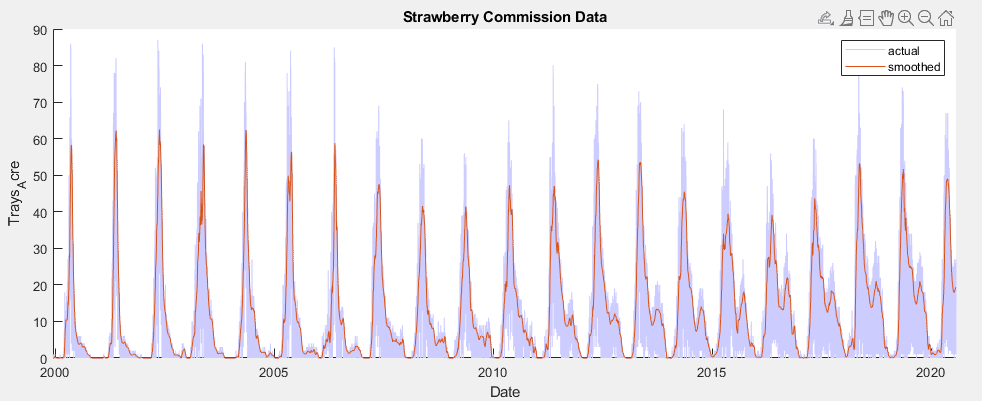
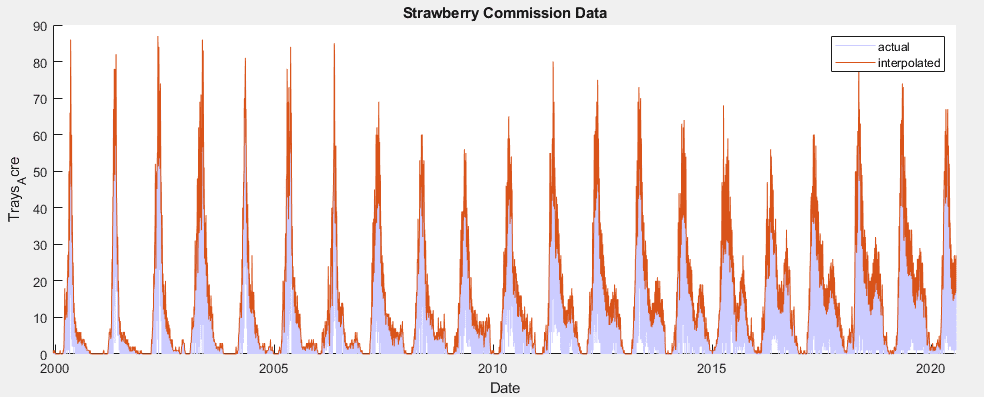
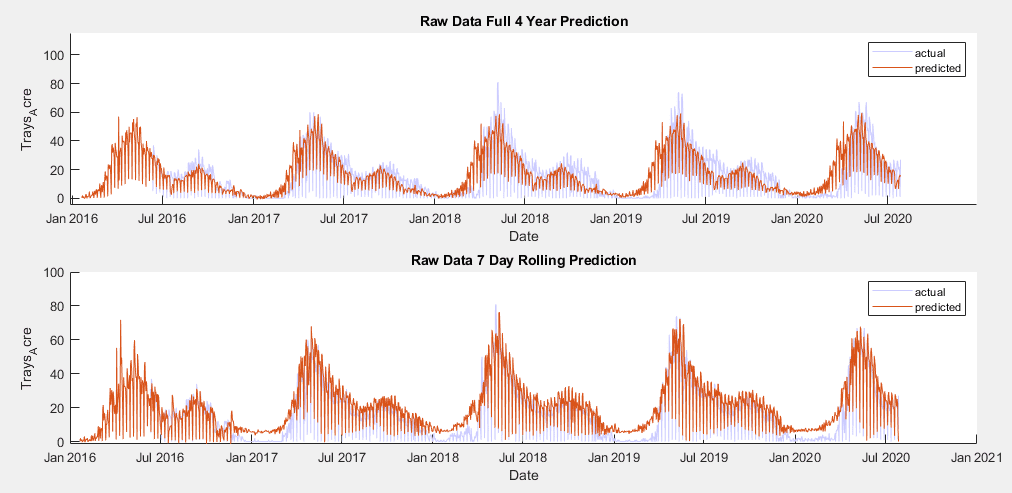
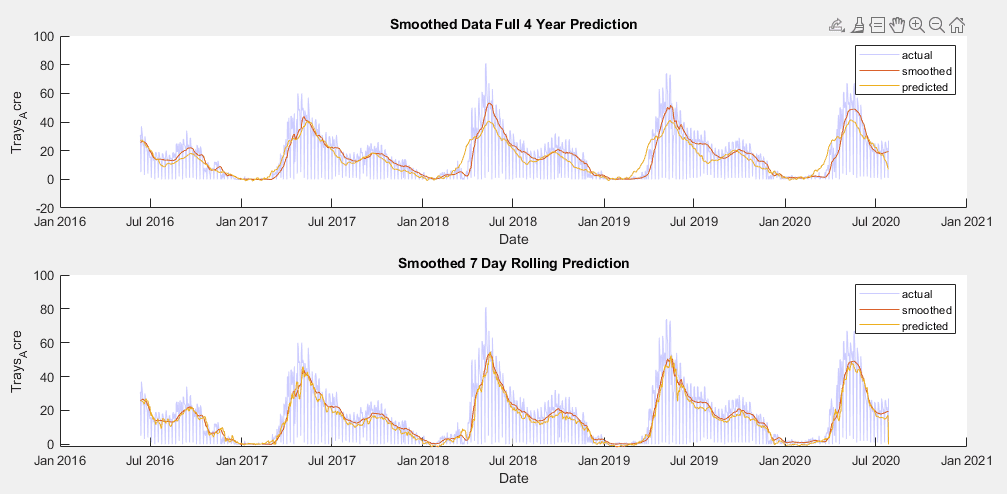
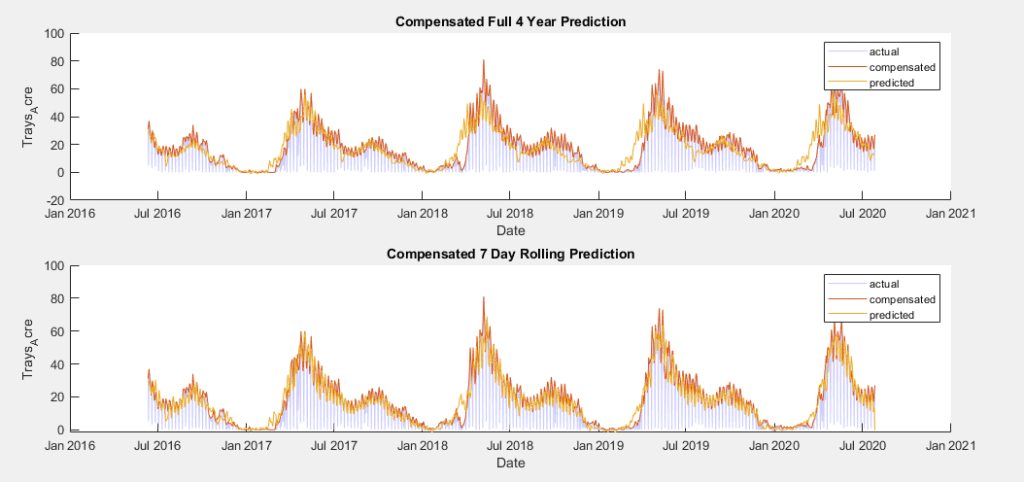
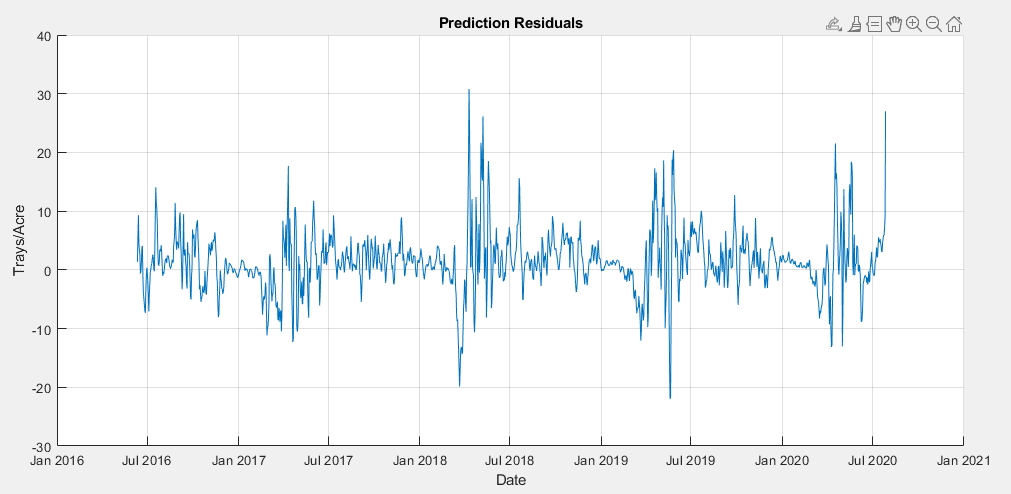
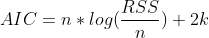In developing a time series model for this data, the implementation of a SARIMAX model became a clear frontrunner early on, over MLR, EGARCH, GJR and ARIMA models. The seasonal nature of the data allowed for a strong prediction using the previous year’s data, autoregressive terms were able to utilize short term weekly trends, moving average terms predicted based on broader trends, and weather variables could be added as exogenous predictors.
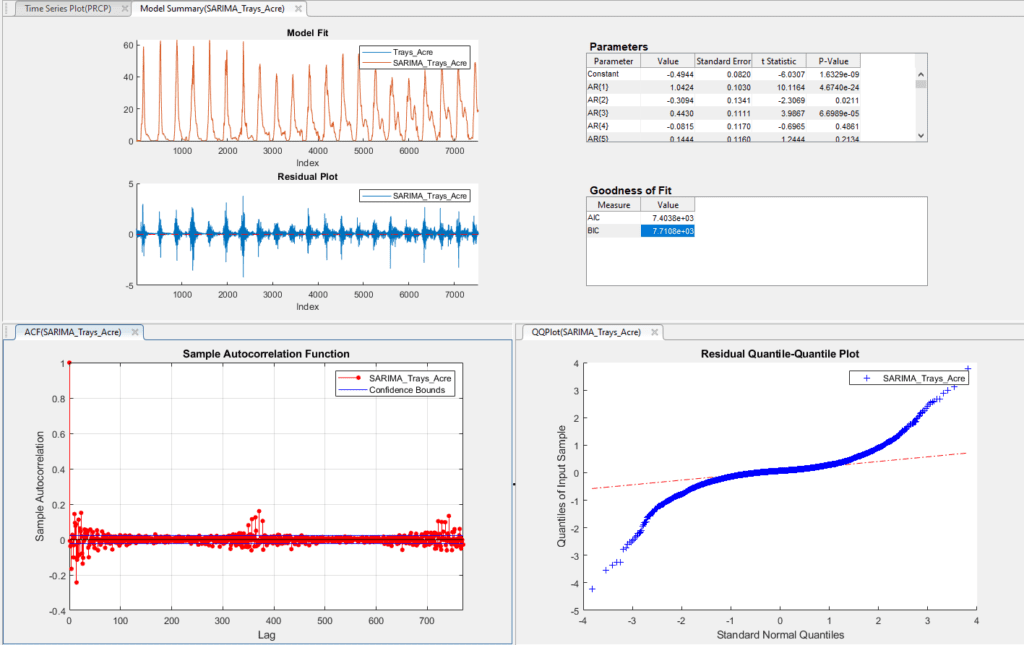
To test for the best possible model, models were trained using the training sets and parameters were raised and lowered individually to determine their effect on the AIC value of the fit. This AIC was then compared across models, with the lowest AIC values indicating the best fitting. While increasing any parameter but the integral order generally improved the fit, seasonal autoregressive and moving average orders had the largest effect. The SARIMAX model with the lowest AIC was one with a moving average order of 30(θ terms in model equation), an autoregressive order of 10(ϕ terms), a seasonal moving average order of 2(Θ terms), a seasonal autoregressive order of 1(Φ terms), a seasonal lag of 365, and average temperature, maximum temperature, minimum temperature and precipitation as exogenous predictors(β terms). Three versions of this model have been trained. One for the raw data and two for each of the preprocessed data sets.